SETA - SElf-driving TA-xi service
Distributed and Pervasive Systems courses, Jun 2022, M.Sc. in Computer Science @UniMi
About the project
Project for the course of “Distributed and Pervasive Systems” A.A. 2021/2022 for M.Sc.’s in Computer Science.
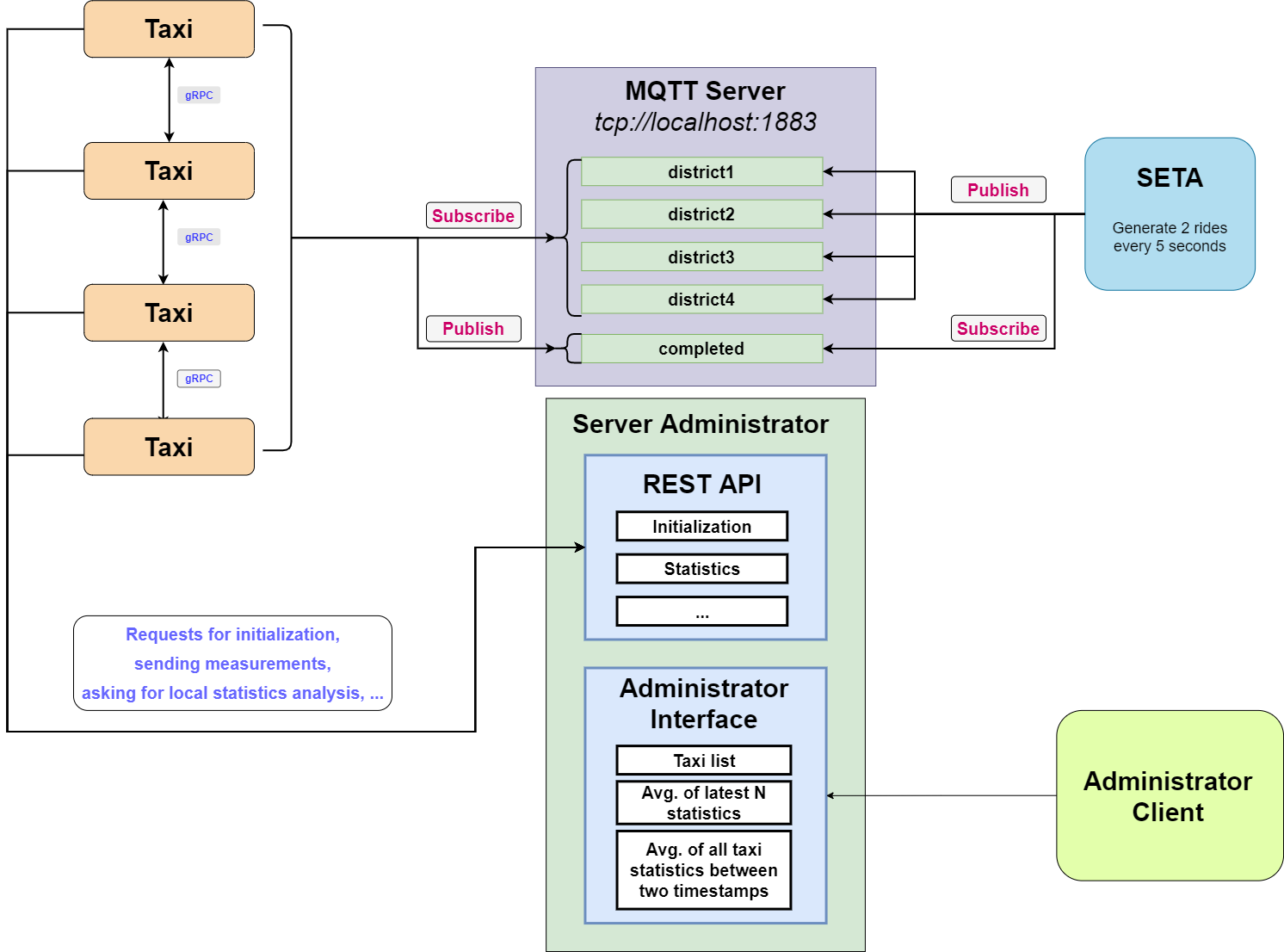
The objective of the project is to design and develop SETA (Self-driving TAxi service), a Self-driving peer-to-peer taxi system for citizens of a smart city. The systems run on a centralized MQTT server which manages the taxis, they are able to communicate with each other via gRPC to ensure access to the resource.
Dev Tools & Languages
Languages
Technologies
Tools
- IntelliJ IDEA
- draw.io for drawing diagrams
- Git & GitHub as versioning system
Within this README are different conceptual diagrams that broadly define the general operation of the system, distributed algorithms, and synchronization procedures.
These diagrams do not rigidly follow any model as they are simple and extensively commented.
Guidelines
- Rhombuses correspond to flow controls.
- Rectangles to of operations/procedures.
- Green circles are collection points.
- Rectangle colors stand for an object belonging to a certain class (so if there are multiple rectangles of the same color, they are multiple instances of the same class).
- White circles correspond to processes (used in diagrams for distributed algorithms).
- Gray circles correspond to threads (used in diagrams for synchronization).
General functioning of the project
This is an outline of general operation of the system, it corresponds to what is required in the assignment delivery document.
Distributed algorithms diagrams
Ricart & Agrawala algorithm for mutual exclusion
The algorithm was developed for guarantee the mutual exclusion to a critical section between multiple processes in a distributed system.
The timestamps of the messages are sent in broadcast (in parallel) through the gRPC call coordinateRechargeStream(). The logical clock synchronization is guaranteed through Lamport’s algorithm.
Consider the following diagram: the nodes in red want to access the critical section, while the other nodes are doing something else.
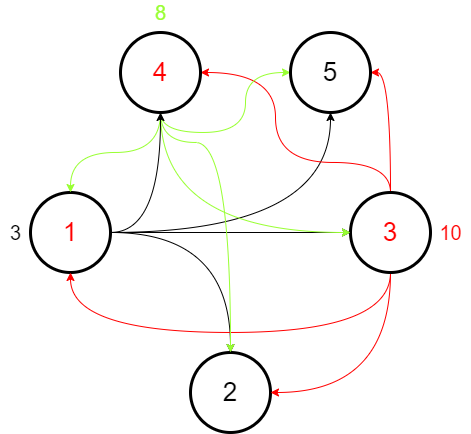
In more depth, in the first phase (in which the requests are parallelized), the processes will build their lists of dependent nodes. These lists will contain all the nodes which got a smaller timestamp relative to theirs.
A node will be able to enter a critical section (i.e., the recharging operation in this project) if it receives acknowledgments from all other nodes. If this doesn’t happen, it will have to wait for the remaining acknowledgments.
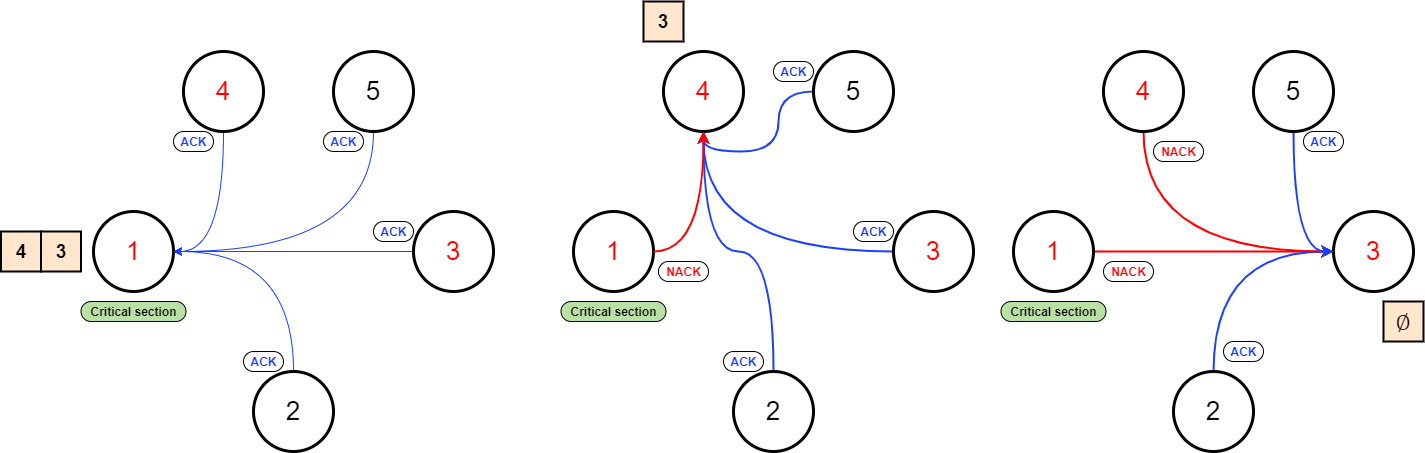
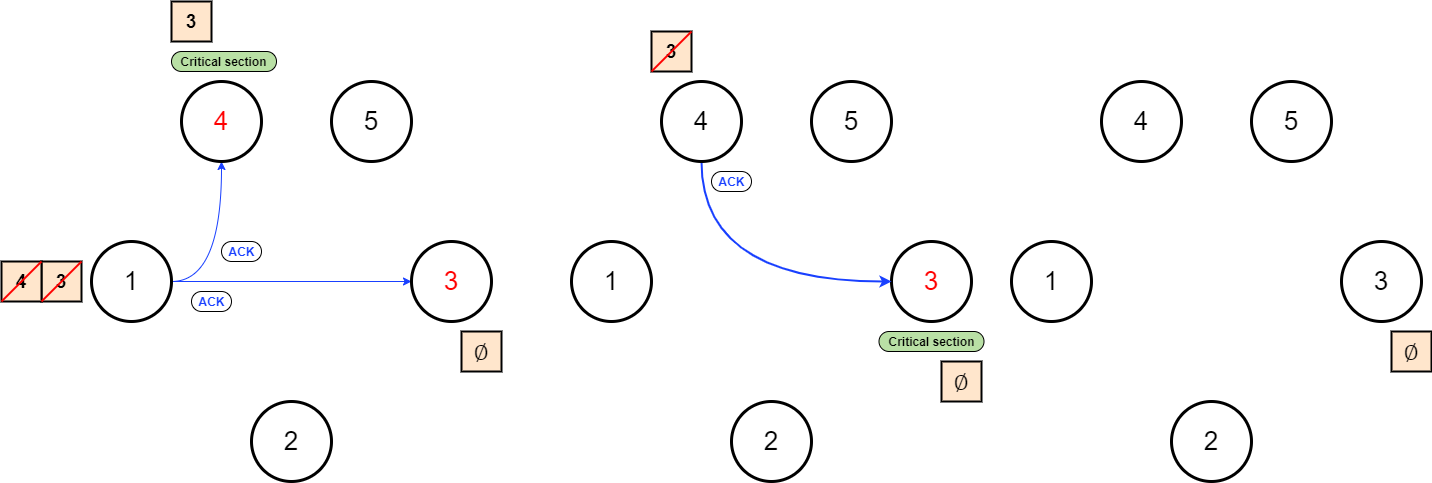
Once a node has finished the recharging operation, it sends an ACK message to the taxis in its list/queue. The first taxi to receive the required number of acknowledgments will access the critical section, and then the process repeats.
Ride election algorithm
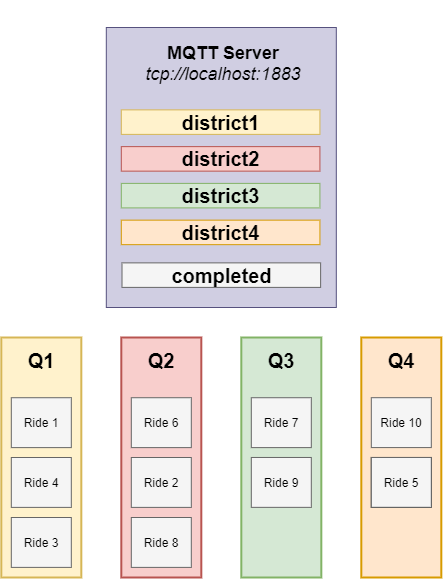
The SETA process generates two rides each 5 seconds on a random district, these two rides are posted on the respective topic of the district. Each taxi is subscribed only on the topic of the district in which it currently belongs.
For simplicity, let’s assume only one ride (ride 5) is published by the SETA process on the first district. All processes subscribed to this topic (inside the green circle) will receive the message for ride 5.
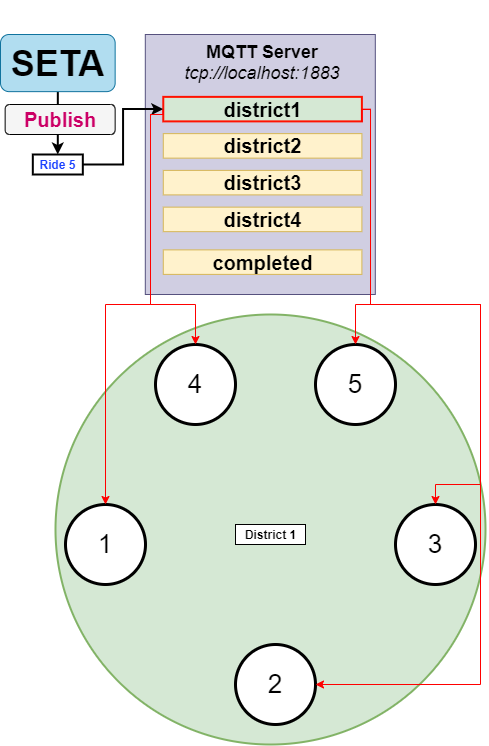
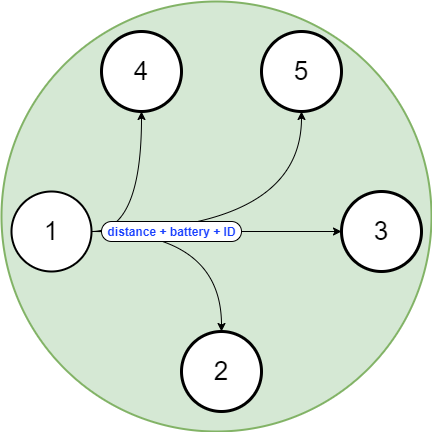
An election mechanism will start through the gRPC call coordinateRideStream(). The request will be broadcast (including to taxis outside district 1) and executed in parallel. The request will contain the Euclidean distance to the starting point, the battery levels and the ID of taxi which is sending the request.
For simplicity, we are examining the evolution of the algorithm from the perspective of process 1.
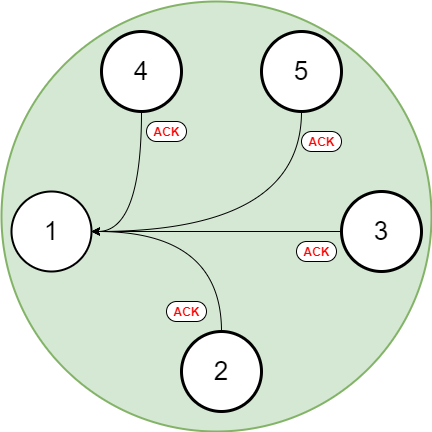
Let’s also assume that process 1 has the smallest distance from the ride’s starting point. Essentially, this means that the taxis receiving the request will all answer with an ACK (meaning they have a worse distance, battery level, or greater ID than process 1). Only then will process 1 achieve consensus.
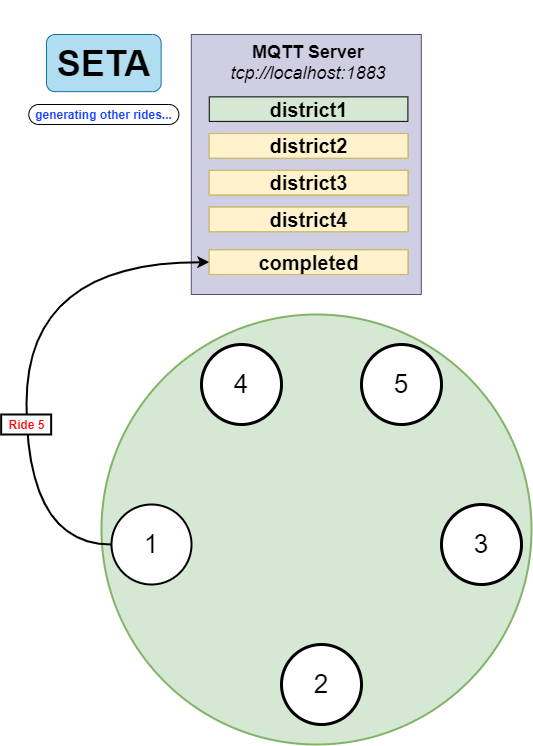
Now process 1 can execute ride 5. Before it passes to local execution of the ride, it publishes a message containing ride 5 on the seta/smartcity/completed topic. This allows stopping the recycling of this message (we will see what this is below) and informs taxis which rides to ignore since they are already taken.
This is because all taxis will have a local list containing all the completed rides from the topic, so they know which rides to avoid.
Ride recycling
A system enforces ride recycling. Each ride generated on the topics is embedded within the respective district queue. The queue priority is based on ride generation order (ride ID), so older rides are preferred.
Conceptual schemes of synchronizations
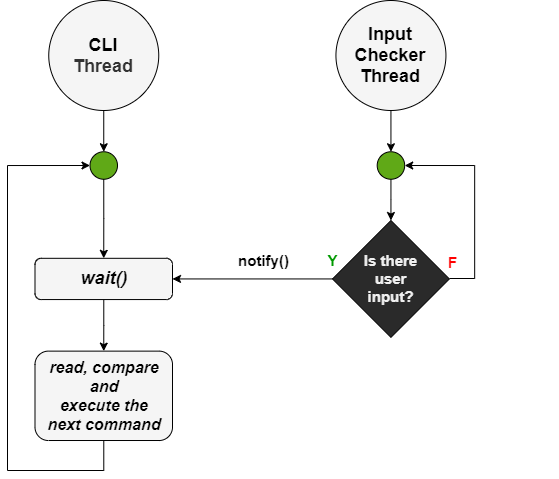
User input
Command entry by users is handled by two threads. One thread for reading and executing the commands entered (CLI, Command Line Interface), and one thread for controlling the input stream (Input Checker).
This approach is designed in such a way as to avoid “busy waiting” phenomena. There is a shared dummy object between the two objects; the thread for the CLI waits to receive an encoding on this object, notification will be sent by the Input Checker when the presence of user input is detected.
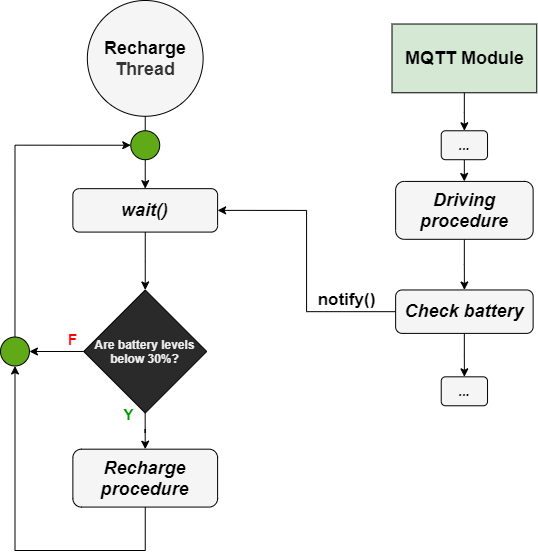
Recharge operation
A thread monitors cab battery levels (Recharge Thread). To avoid “busy waiting” phenomena, a dummy object is shared between this thread and the MQTT module.
The recharge thread is initially waiting and will check the battery levels only after receiving the notification on the shared dummy object.
The MQTT module receives ride messages for its own district, and its callbacks can call methods (which function like threads). Upon completion of the function that handles the ride, we notify the dummy object through notify().
This way, a battery level check is made after a ride is finished. The charging procedure will only be started if the battery levels are below 30 percent.
Local statistics
The collection and submission of local statistics involves different agents :
- A PM10 simulator that generates random measurements of pollution levels at a random cadence.
- A Pollution Buffer which is a data structure used for the collection and self-management (sliding window technique) of measurements generated by the PM10 simulator.
- A thread for reading the PM10 measurements buffered in the Pollution Buffer, with addition of the other local statistics (total traveled km, battery levels, accomplished runs, …) and subsequent sending on the administrator server via POST request (Local Stats Thread).
- A thread to ensure local statistics are sent every 15 seconds (Enable Data Send Thread).
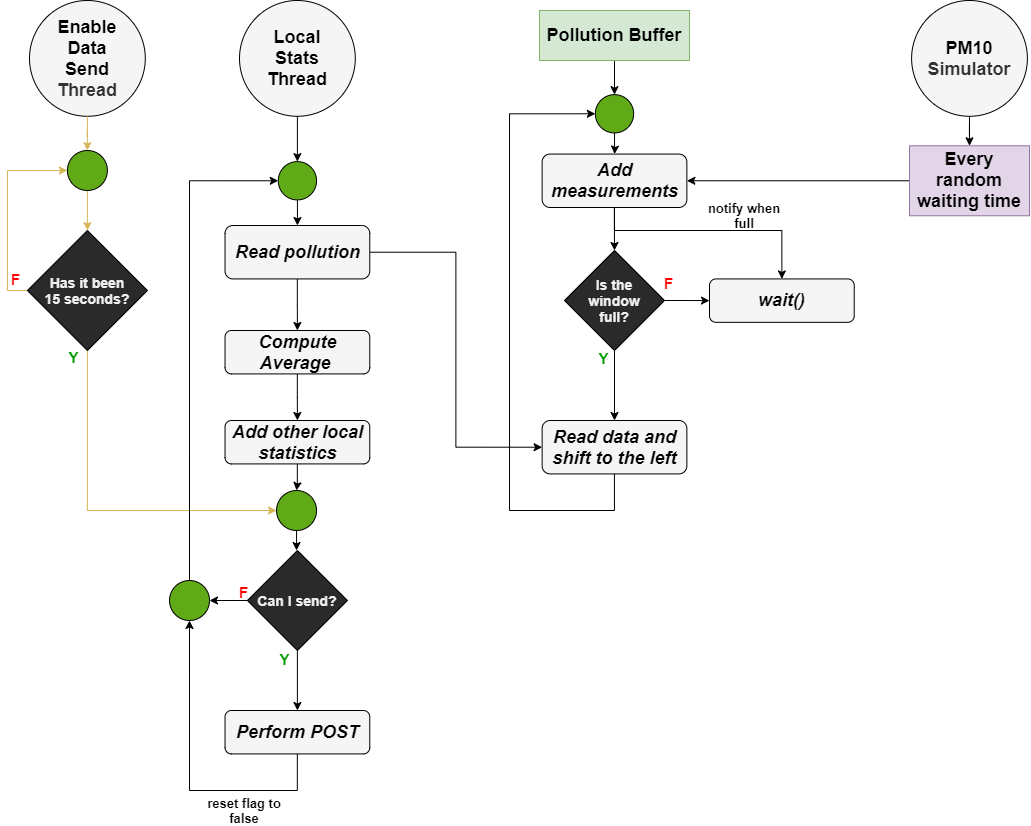
The Local Stats Thread reads the measurements, but its operation is governed by the Pollution Buffer’s internal data structure.
Once the array of measurements is read, its average is calculated. Then a data structure is created that contains both this average and the other local statistics:
- Total traveled kilometers
- Battery levels
- Total accomplished runs
Every fifteen seconds, a POST request sends this data structure to the administrator server. To ensure this, a thread (Enable Data Thread) sets a boolean (initialized to false) to true.
The Local Stats Thread checks this boolean. If it is true, the POST request is executed.
Then the flag will be set to false again, and it will wait 15 seconds to be reactivated.
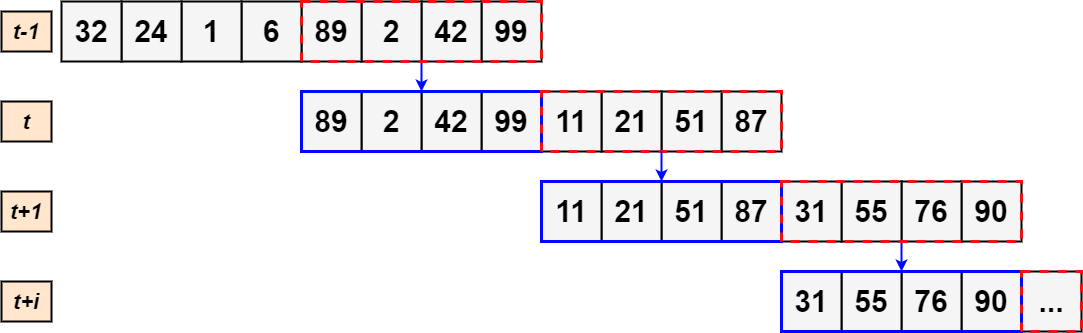
Sliding window
The Pollution Buffer presents a method that is constantly called at an unknown time by the PM10 simulator. The Pollution Buffer internal structure consists of a sliding window of 50% of size 8 (each element is a PM10 measurements).
Once the internal data structure reaches maximum capacity, the Local Stats Thread will read it. The read operation involves a left shift of 50% of the elements (i.e., 4 elements), after which the elements added by the PM10 simulator will be allocated starting from the fifth. When the eighth element is added again, a new reading of the sliding window can be performed.
In this way, the various sliding windows that are read will share four elements. That is, the sliding window of iteration t-1 will have the same last four elements as the first four elements of the sliding window at time t.
Manuel Pagliuca
Software Engineer
My interests concern Distributed Systems, Payments, Artificial Intelligence.